1. 概况
集群节点规划:
| 序号 | 主机名 | IP | 角色 |
|---|---|---|---|
| 1 | es1 | 192.168.6.171 | master|data(主节点|数据节点) |
| 2 | es2 | 192.168.6.172 | master|data(主节点|数据节点) |
| 3 | es3 | 192.168.6.173 | master|data(主节点|数据节点) |
版本信息:
| 名称 | 版本 |
|---|---|
| 操作系统 | CentOS Linux release 7.9.2009 (Core) |
| Linux内核 | 5.4.229-1.el7.elrepo.x86_64 |
| elasticsearch | v8.6.0 |
| kibana | v8.6.0 |
【所有ES节点操作】
cat >> /etc/hosts << EOF
192.168.6.171 es1
192.168.6.172 es2
192.168.6.173 es3
EOF2. 基础配置与准备
【所有ES节点上操作】
关闭防火墙:systemctl disable firewalld --now
禁用swap:swapoff -a
设置正常不用swap(除非情况紧急):
echo "vm.swappiness = 1" && /etc/sysctl.conf
使生效:sysctl -p系统参数调整:
(1)调整limits配置
临时:
ulimit -SHn 65536永久:
cat >> /etc/security/limits.conf << EOF
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
* soft memlock unlimited
* hard memlock unlimited
EOF注:ES8要求最小是65536,memlock unlimited 也是刚需。
(2)调整vm.max_map_count
vim /etc/sysctl.conf,追加:vm.max_map_count=655360
使生效:sysctl -p(3)注意:安装 elasticsearch 8+ 时,linux 内核必须是4+,否则,很可能有坑!
创建软件目录:mkdir /soft && cd /soft
下载elasticsearch:https://www.elastic.co/cn/downloads/elasticsearch
下载 elasticsearch-8.6.0-linux-x86_64.tar.gz 到 /soft
下载kibana:https://www.elastic.co/cn/downloads/kibana
下载 kibana-8.6.0-linux-x86_64.tar.gz 到 /soft
【所有ES节点上操作】
创建ES主目录:mkdir /data/elasticsearch
解压软件包:tar -zxvf elasticsearch-8.6.0-linux-x86_64.tar.gz -C /data/elasticsearch --strip-components 1
cd /data/elasticsearch【es1上操作(先只在es1上安装kibana)】
创建kibana主目录:mkdir /data/kibana
解压软件包:tar -zxvf kibana-8.6.0-linux-x86_64.tar.gz -C /data/kibana --strip-components 1【所有ES节点上操作】
cd /data/elasticsearch
设置环境变量:
vim /etc/profile,追加:
# elasticsearch8.6
export ES_HOME=/data/elasticsearch
export PATH=$ES_HOME/bin:$PATHsource /etc/profile
验证:elasticsearch -V 或 elasticsearch -version
注意:elasticsearch默认禁止用root账号启动。
创建es组和用户:
groupadd es
useradd -g es es
注:无需设置密码,未设密码的用户是禁止登录的。修改目录所属:
chown -R es.es /data/elasticsearch //【所有es节点上操作】
chown -R es.es /data/kibana //【es1上操作】JVM参数调整:
vim config/jvm.options
----------------------S
-Xms4g
-Xmx4g
-XX:NewSize=2G
-XX:MaxNewSize=2G
----------------------E
注:物理机内存约8G。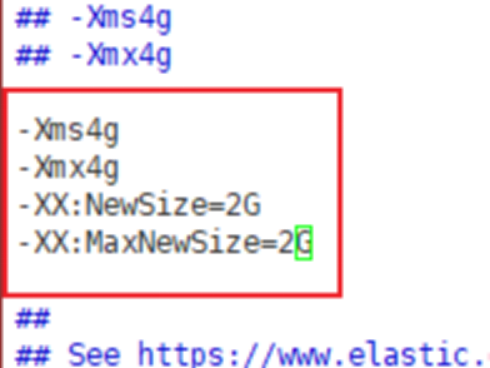
3. 先运行一个ES节点
【es1上操作】
切换到es用户:su es
cd /data/elasticsearch/config
vim elasticsearch.yml(追加在末尾):
cluster.name: es-cluster
node.name: es1
node.roles: [master, data]
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
network.host: 192.168.6.171
http.host: 0.0.0.0
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 200mb
bootstrap.memory_lock: true
ingest.geoip.downloader.enabled: false
action.destructive_requires_name: true后台运行:elasticsearch -d

注:重配重启,别忘了kill掉守护进程(用root账号ps -ef查看相关残留进程)。
4. 安装kibana在es1节点上
【es1上操作】
cd /data/kibana
vim config/kibana.yml,追加:
server.host: "0.0.0.0"
server.port: 5601
i18n.locale: "zh-CN"后台运行kibana:
nohup bin/kibana &
tailf nohup.out
注:如用root用户启动kibana,启动时加上参数 --allow-root。通过 ss -luntp | grep 5601 看有无之前残留的kibana进程。访问(注意本地hosts配置):http://es1:5601
生成集成kibana的token:
elasticsearch-create-enrollment-token --scope kibana
查看验证码:
./bin/kibana-verification-code
此时,查看kibana.yml,会多出来(自动生成部分):

重置elastic用户(最高权限)的密码:
elasticsearch-reset-password -u elastic验证(用elastic登录):
5. 扩展es集群节点到3个
【es1上操作】
再次生成其他节点加入集群的token(30分钟有效期):
elasticsearch-create-enrollment-token -s node
【es2上操作(切到es用户)】
cd /data/elasticsearch/config
vi elasticsearch.yml(追加在末尾):
cluster.name: es-cluster
node.name: es2
node.roles: [master, data]
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
network.host: 192.168.6.172
http.host: 0.0.0.0
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 200mb
bootstrap.memory_lock: true
ingest.geoip.downloader.enabled: false
action.destructive_requires_name: true后台运行,加入集群中:
elasticsearch -d --enrollment-token eyJ2ZXIiOiI4LjYuMCIsImFkciI6WyIxOTIuMTY4LjYuMTcxOjkyMDAiXSwiZmdyIjoiYWZiNDE3OTM5MzhlOTE2ZjllMmI4ODlhN2FhZGU4NDUwMGRjMzI1Yjk5OTMxNjEyZDVhZGU3NmY1NDFlY2ZhMyIsImtleSI6IjZlVU84WVVCRFdPR2RoaHgtWjA1OmxPUkFXZ1V0Ukwtd1BhNFQ1cjFaUncifQ==
【es3上操作(es用户)】
cd /data/elasticsearch/config
vim elasticsearch.yml(追加在末尾):
cluster.name: es-cluster
node.name: es3
node.roles: [master, data]
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
network.host: 192.168.6.173
http.host: 0.0.0.0
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 200mb
bootstrap.memory_lock: true
ingest.geoip.downloader.enabled: false
action.destructive_requires_name: true后台运行,加入集群中:
elasticsearch -d --enrollment-token eyJ2ZXIiOiI4LjYuMCIsImFkciI6WyIxOTIuMTY4LjYuMTcxOjkyMDAiXSwiZmdyIjoiYWZiNDE3OTM5MzhlOTE2ZjllMmI4ODlhN2FhZGU4NDUwMGRjMzI1Yjk5OTMxNjEyZDVhZGU3NmY1NDFlY2ZhMyIsImtleSI6IjZlVU84WVVCRFdPR2RoaHgtWjA1OmxPUkFXZ1V0Ukwtd1BhNFQ1cjFaUncifQ==
查看结果:

6. 配置ES相关系统服务(开机自启)
【所有ES节点上操作】
增加/调整配置(es用户执行):
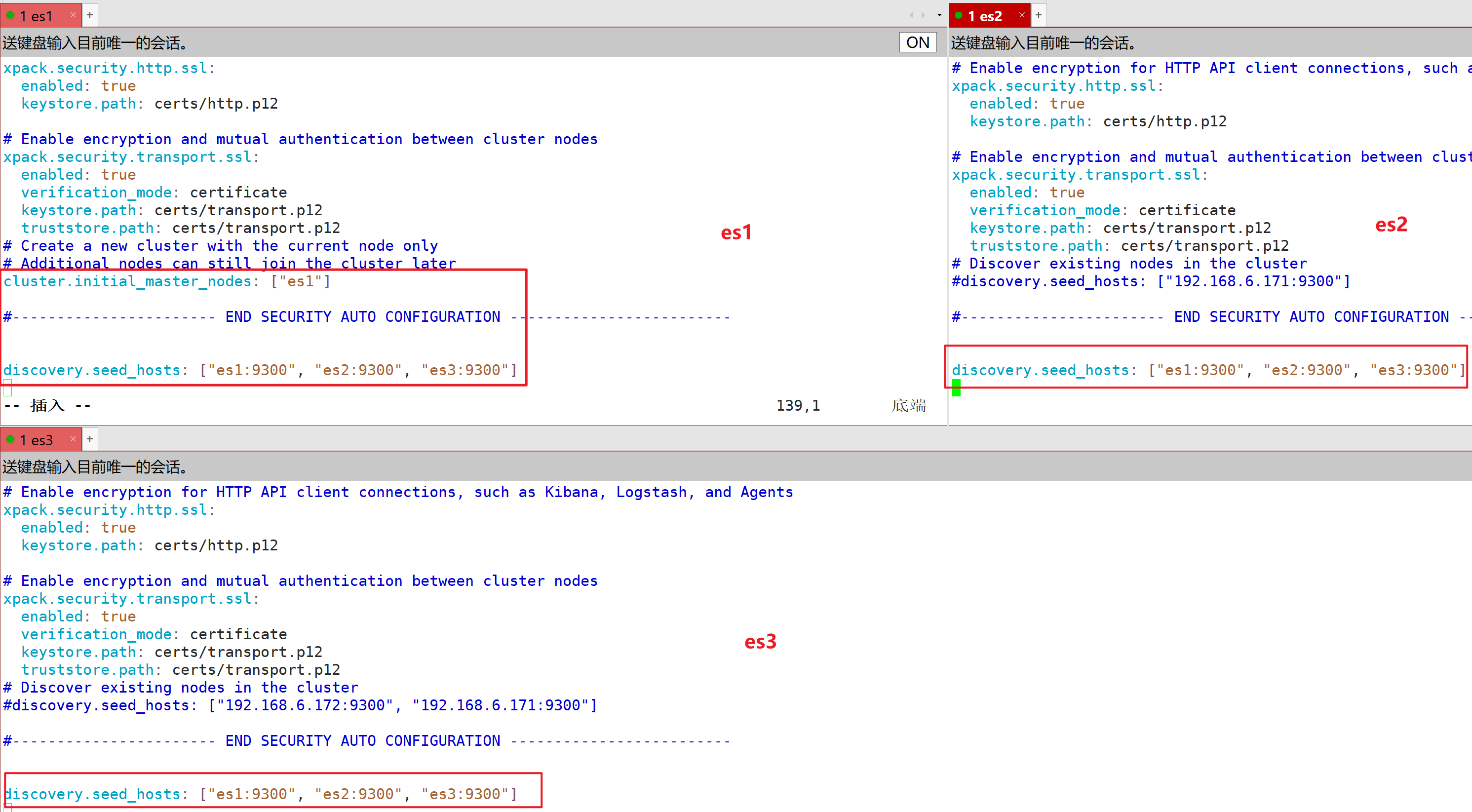
cluster.initial_master_nodes: ["es1", "es2", "es3"]
discovery.seed_hosts: ["es1:9300", "es2:9300", "es3:9300"]
注:以下截图均需修正为:cluster.initial_master_nodes: ["es1", "es2", "es3"](每个es节点都是这样配置的,除非不止这三个节点是master角色!)
创建ES系统服务(root用户执行):
vim /usr/lib/systemd/system/elasticsearch.service
[Unit]
Description=elasticsearch
After=network.target
Wants=network.target
[Service]
User=es
Group=es
LimitNOFILE=165536
LimitNPROC=165536
LimitMEMLOCK=infinity
ExecStart=/data/elasticsearch/bin/elasticsearch
[Install]
WantedBy=multi-user.target注:一般情况下,先杀掉正则匹配到elasticsearch的进程(kibana的进程也一并被杀了):
kill -9 $(ps -ef |grep elasticsearch |grep -v grep |awk '{print $2}')
systemctl daemon-reload
systemctl enable elasticsearch --now创建kibana系统服务:
【es1上操作(root用户执行)】
vim /usr/lib/systemd/system/kibana.service
[Unit]
Description=kibana
After=network.target
Wants=elasticsearch
[Service]
User=es
Group=es
ExecStart=/data/kibana/bin/kibana
[Install]
WantedBy=multi-user.targetsystemctl daemon-reload
systemctl enable kibana --now查看集群健康状态等信息:
a. 查看集群健康状态
GET _cat/health
GET _cat/health?v
b. 查看集群节点信息
GET _cat/nodes
GET _cat/nodes?v
c. 查看集群索引信息
GET _cat/indices
GET _cat/indices?v
7. 安装IK分词器
【所有ES节点上操作】
注:与elasticsearch版本要一致(下载 elasticsearch-analysis-ik-8.6.0.zip)。
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v8.6.0
su es
cd /data/elasticsearch/plugins
mkdir ik && cd ik
将elasticsearch-analysis-ik-8.6.0.zip上传到ik目录下。
解压:unzip elasticsearch-analysis-ik-8.6.0.zip
Ctrl+D 退出es用户,重启es服务即可:
systemctl restart elasticsearch
注:若用 systemctl status elasticsearch 查看,立马正常,端口9200要过一会儿才能出来。
8. 优化ES集群配置
(1)解决 kibana 出现的 Client request timeout 问题
【es1(kibana)节点上操作】
修改 kibana.yml:
将:
#elasticsearch.requestTimeout: 30000
改为:
elasticsearch.requestTimeout: 3000000(2)解决数据迁移时的报错
报错:org.elasticsearch.client.ResponseException: method [POST], host [http://192.168.6.171:9200], URI [/demo/_bulk], status line [HTTP/1.1 413 Request Entity Too Large]
【所有es节点上操作】
修改 elasticsearch.yml:
将:
http.max_content_length: 200mb
改为:
http.max_content_length: 2000mb
注:也不能太大,否则会导致报错:
java.lang.IllegalArgumentException: failed to parse value [20000mb] for setting [http.max_content_length], must be <= [2147483647b](3)解决java通过DSL的script操作时的报错
报错:"[es/put_script] failed: [illegal_argument_exception] exceeded max allowed stored script size in bytes [65535] with size [502007] for script [dsl1]"
【所有es节点上操作】
修改 elasticsearch.yml:
追加:
script.max_size_in_bytes: 10000000(4)解决java通过DSL的script操作时的报错
报错:[script] Too many dynamic script compilations within, max: [150/5m]; please use indexed, or scripts with parameters instead; this limit can be changed by the [script.max_compilations_rate] setting
【所有es节点上操作】
修改 elasticsearch.yml:
追加:
script.max_compilations_rate: 60000/1m
其他:
# index_buffer
indices.memory.index_buffer_size: 15%
indices.memory.min_index_buffer_size: 96mb
# 用于 Get 请求的线程池(queue_size默认为1000)
thread_pool.get.queue_size: 5000
# 用于 index/delete/update/bulk 请求的写线程池(queue_size默认为10000)
thread_pool.write.queue_size: 20000
# 用于 count/search/suggest 等操作的搜索线程池(queue_size默认为1000)
thread_pool.search.queue_size: 5000